カテゴリー: Tech blog
Bigqueryの統計情報のクエリプランへの影響の検証
2023年12月19日Index##概要##環境&手順 テストデータ 性能確認手順##検証 検証1:Bigqueryは項目の保有する最大値、最小値を把握しているのか? 検証内容 検証結果 考察 検 […]
Bigquery 性能検証
2023年12月19日Index##概要##環境&手順 テストデータ 性能確認手順##Bigqueryの性能検証 Bacic目的検証結果 考察##Bigqueryの性能検証 Advanced目的検証結果 1.パーティションキー&クラスターキーを指定した場合のスキャン開始位置 考察 […]

掲示板WEBサイトの投稿分析機能
2023年12月19日Index##機能概要##最終アウトプットのサンプルイメージ##システム構成##前提 基本技術の説明について WEBからのデータ抽出について##処理プロセス 処理コード全体(bashのスクリプト) 環境変数の設定 事前のワークファイルの削除 Pythonでスクレイピン […]

Bigqueryテストデータ生成 – 1億件を10秒で! –
2023年12月19日Index##機能概要##以降で説明するコードの全体像##データ生成手順 テーブル作成 データ生成##データ生成結果##おまけ テーブル作成 データ生成##データ生成結果 ※ 下記のgithubでも同様の内容を公開しています。gitの方が見易い方は下記を参照してください。 ##機能概要 Bigqueryは大量デ […]

データアクセスパスのパターン化
2023年8月23日デザインパターンというものがある。classをデザインするときのパターンを汎化してまとめたものである。多くのデザインがこのパターンのどれかに近いもので実現できる。 データアクセスパスも同じようにパターンを型として理解しておけば、その型をベースに多様な状況に対応できる。 下記にデータアクセスをパターン化して型として整理する。 概要(型の使い方) 1.アクセスパターン 参考)サイジング:ストレージ 2 […]

※作成中※ ETLの並列処理(概要)
2023年8月16日ETLは並列化することで高速化できる。しかし、並列化には多くのパターンがあり適切に選択しなれば効果が得られない。並列化のパターンとそのメリット、デメリットを記載する。
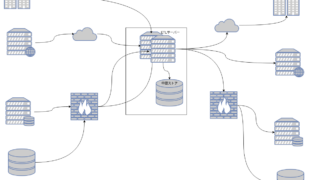
ETLのウィークポイント(システム移行)
2023年8月6日Index システム移行方式のパターン ETLに適したシステム移行方式 ETLのシステム移行のリスク対策ETLはソフトウェアのバージョンアップ、ハードウェアのリソース不足、老朽化等でシステム移行が必要となる。ETLは非常に多くのシステムと接続するためこのシステム移行には労力とリスクを伴う。 特に、ETLが全社的に活用され接続先が多い […]
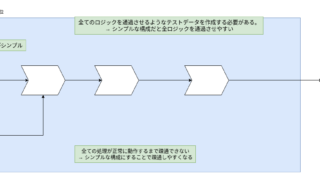
ETLのウィークポイント(修正とテスト)
2023年8月2日Index スクラッチ開発の場合の修正とテスト ETLの場合の修正とテスト ETLのウィークポイントとどう付き合うか?ETLは生産性が高いと言われるが必ずしもそうではない。スクラッチ開発よりも弱い部分がある。率直に言うと、ETLは新規のアプリ作成は生産性が高い。一方、以下の特性から修正には弱い。 下記にウィークポイントの詳細と対策を […]
ETLのサイジング:ストレージ
2023年8月2日ETLサーバーの内部ストレージは以下のような用途で使われる。 多くの場合はシーケンシャルIOであるが、上記2はランダムIOである。下記にシーケンシャルIO、ランダムIO、それぞれのサイジングの考え方を記載しているので参照してほしい。 サイジング:ストレージ
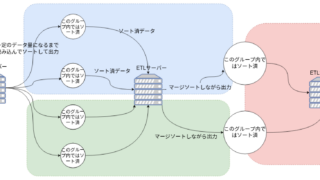
ETLのサイジング:メモリ
2023年8月2日ETLのメモリはDBのように、アクセス頻度の高いデータをメモリに載せてディスクアクセスの頻度を削減するような使い方はしない。 ソート、ソートJOIN、Group by、ランキング処理等のレコード間の関連を見なければならない処理では、メモリにデータを溜める必要がある。もし、メモリが足りなければディスクの一時領域に保管される。 重要な処理について目標処理時間を達成するために、上記の処理についてメモリを […]
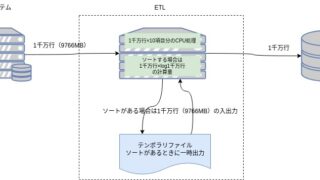
ETLのサイジング:CPU
2023年8月1日ETLのCPUをサイジングするときの基本的な考え方を記載する。いろいろなサイジング方法があるが私が使っているものである。常に実測してみて見積るのでは作業コストが膨らんでしまう。また、実測はテストデータの特性やキャッシュの状態に依存し精度の高い測定はかなり難しい。 重要度の低い処理はシュミレーションのみでサインジングして、重要な処理では実測とシュミュレーションで大きな差がないことを確認するアプローチ […]

サイジング:HDD vs SSD
2023年7月30日Index HDD SSD シーケンシャルIOがランダムIOと比較して高速となる原理最近はほとんどのケースでSSDでストレージを構成する。HDDとSSDではシーケンシャルIOの特性に違いがあり、SSDをHDDの場合と同じように考えてサイジングすると想定外の性能問題になる可能性がある。本記事は両者のシーケンシャルIOの特性の理解を目的 […]

サイジング:ストレージ
2023年7月28日Index ランダムIO シーケンシャルIO IO回数と処理時間クラウドでサーバーのディスクストレージを選択する時、どのように選択するべきか基準がわからない人が多いのではないだろうか。データ基盤のボトルネックの多くはストレージのIOで発生する。ストレージのIOの仕組みを理解し、適切にサイジングできるようになることは重要なスキルであ […]

データストア(データベース)の選び方
2023年7月26日時代の流れとともにニーズが変化しデータソースの機能も進化してきた。しかし、いろいろなタイプのデータベースが存在するのはなぜだろうか。理由はデータの整合性、同時書き込み、大量データの処理、大量のトランザクションのどれかを強化しようとすると何かが犠牲になってしまうからである。コストを掛ければ全てを満すことも不可能ではないようだが今のところ現実的ではない(CAP定理)。 データ量が少ない時代では、RDB […]
Tech Blogのコンセプト
2023年7月26日Tech Blogでは中級者以上の技術者向けにデータエンジニアの領域についての情報を提供する。25年以上、SIerの技術者として現場で手を動かしてきた(About参照)。そのアドバンテージを活かし、付加価値の高いコンテンツを目指す。 ”初心者でもわかるような詳細さ”や”正確さ”は本質が伝わりにくくなるデメリットから重視していない。要望があれば、コメント欄に記載いただきたい。

データ連携基盤のサイジングの考え方
2023年7月26日Index 超概要 概要 詳細データ連携基盤をサイジングするときのポイントをまとめる。 超概要 1.目標設定最も重たいかつ重要な処理について目標の処理時間を設定する。 2.ボトルネックの特定 重要な処理がIOボトルネックかCPUボトルネックか評価する。 3. サイジングボトルネックについて目標時間をクリアできるようにハードウェアをサ […]

データ連携基盤の基本アーキテクチャー(クラスタ構成)
2023年7月23日可用性と性能を考慮したデータ連携基盤のアーキテクチャを記載する。 要件が単純な場合は、”ソースシステム→ETL→ターゲット”がそれぞれ単体で存在するようなシンプルな構成となる。しかし、データ連携基盤の活用が進み停止が許されないようになると可用性を考慮して多重化する必要性が出て来る。さらに、単体で性能を満たせいないような要件が出てくると多重化したサーバーを同時に並列稼動させる必要がある。また、ETL […]
DB実行計画の”コスト”の考え方を理解する
2023年7月23日Index コストの目的 コストの使い方(概要) コストの使い方(詳細) 実際のデータベースでのコストの例 参考(Postgresqlのマニュアルから抜粋)データベースの実行計画のマニュアルや解説で下記の図のようなコストという概念が出て来る。私はデータベースの実行計画を勉強し始めたころ、こ […]

CPU、ストレージ、NWの処理時間を”体系的”に理解する
2023年7月22日システムの処理時間はCPU、ストレージ、ネットワークの処理時間の合計である。それぞれの処理時間の規模感が理解できるとパフォーマンスチューニングでどこがボトルネックか判断できるようになる。 例えば、DBからのレスポンスタイムが3秒だったとき、「CPUで数マイクロ秒、IOで数秒、NWで数ミリ秒でほとんどがIOの処理時間だろう」というように規模感がわかればどこにフォーカスするべきか判断できる。また、実測 […]
データ基盤の構成要素
2023年7月22日データ基盤を構成する要素を記載する。他のサイトにも存在する情報ではあるがデータ仮想化も含めたフルセットがシンプルに整理されたものが見つからなかったので簡単に記載しておくことにした。 データ加工機能 データ保管機能 集計/分析機能 データ保管機能にはニーズによって以下のようなデータベースが使われる。

DBの実行計画とは
2023年7月21日Index 実行計画の目的 実行計画とはどのように作成されるか?データベースの実行計画がどのようなもので、どのように利用されるか記載する。本質の理解を目的としているため特定のシンプルな構成を例に説明する。 実行計画の目的 実行計画は、ストレージのデータをユーザーに渡すために、ハードウェアをより効率的に使う手順を計画したものである。主に以下のように利用され […]

システム設計で待ち行列理論を活用する
2023年7月20日Index 概要 待ち行列理論の活用方法 参考)待ち行列理論 システム設計での待ち行列の本質待ち行列という理論があり、IPAの情報処理試験にも登場する。実務での活用が難しい理論だと思う。本質を理解して活用できるように体系化する。 概要 システムでの待ち行列は、以下の4つを考える。 例えばCPUとロックだと下記の […]

データ基盤(連携基盤+分析基盤)の進化
2023年7月19日Index データウェアハウス データハブ ビックデータ基盤 ストリーム処理 データ仮想化 データメッシュデータ基盤にはいろいろな種類がある。その結果、データ基盤のイメージは人によって様々である。時代の流れとともにデータ量が増え、ニーズも変わりデータ基盤の構成も進化し […]