※下記のGithubでも公開しています。gitの方が見易い人はこちらを参照してください。
##概要
基本的な機能(パーティション&クラスタリングの効果)に加え、パーティション指定なし&クラスターキー指定なしでの高速化等
Advancedな内容にも踏み込んで検証している。
※ 検証環境や検証用のSQLも下記で公開&説明しているのでご活用ください。
##環境&手順
テストデータ
以下のリポジトリの方法で作成した1億件のテーブルで性能を検証する。
性能確認手順
bq query --use_legacy_sql=false < pf.sql
bq query --use_legacy_sql=false < ev.sql上記のコマンドで対象のSQL実行と性能情報取得を実行している
上記が評価対象のSQL
上記が性能情報取得用のSQL。システムテーブルを使っている。コンソールでも同様の情報が参照できるのでそちらを使って良い。
##Bigqueryの性能検証 Bacic
目的
Bigqueryでテーブルを設計するなら知っておくべき基本的な機能を検証する。
1. パーティションの効果を確認する。
2. クラスタリングの効果を確認する。
検証結果
フルスキャンの場合
select
'pf fullscan',
partid,
clusterdid,
num_col1,
CURRENT_TIMESTAMP() t
from `ml_dataset.bigdata_for_ev`
where num_col1=12091139; -- at [2:1]
+-------------+--------+------------+----------+---------------------+
| f0_ | partid | clusterdid | num_col1 | t |
+-------------+--------+------------+----------+---------------------+
| pf fullscan | 10 | 9700146 | 12091139 | 2023-12-17 02:39:32 |
+-------------+--------+------------+----------+---------------------+
+-----------------------------------+--------------------+-------------------+-----------+
| query | processed_MB | Charges_yen | cache_hit |
+-----------------------------------+--------------------+-------------------+-----------+
| select | 2288.8927001953125 | 2.235246777534485 | false |
| 'pf fullscan', | | | |
| partid, | | | |
| clusterdid, | | | |
| num_col1, | | | |
| CURRENT_TIMESTAMP() t | | | |
| from `ml_dataset.bigdata_for_ev` | | | |
| where num_col1=12091139 | | | |
+-----------------------------------+--------------------+-------------------+-----------+- パーティションの効果を確認する。
select
'pf part',
partid,
clusterdid,
CURRENT_TIMESTAMP() t
from `ml_dataset.bigdata_for_ev`
where num_col1=12091139
and partid = 10; -- at [2:1]
+---------+--------+------------+---------------------+
| f0_ | partid | clusterdid | t |
+---------+--------+------------+---------------------+
| pf part | 10 | 9700146 | 2023-12-17 02:39:59 |
+---------+--------+------------+---------------------+
+-----------------------------------+----------------+----------------------+-----------+
| query | processed_MB | Charges_yen | cache_hit |
+-----------------------------------+----------------+----------------------+-----------+
| select | 22.88818359375 | 0.022351741790771484 | false |
| 'pf part', | | | |
| partid, | | | |
| clusterdid, | | | |
| CURRENT_TIMESTAMP() t | | | |
| from `ml_dataset.bigdata_for_ev` | | | |
| where num_col1=12091139 | | | |
| and partid = 10 | | | |
+-----------------------------------+----------------+----------------------+-----------+- クラスタリングの効果を確認する。
select
'pf part+cluster',
partid,
clusterdid,
CURRENT_TIMESTAMP() t
from `ml_dataset.bigdata_for_ev`
where num_col1=12091139
and partid = 10
and clusterdid=9700146; -- at [2:1]
+-----------------+--------+------------+---------------------+
| f0_ | partid | clusterdid | t |
+-----------------+--------+------------+---------------------+
| pf part+cluster | 10 | 9700146 | 2023-12-17 02:40:59 |
+-----------------+--------+------------+---------------------+
+----------------------------------+-------------------+----------------------+-----------+
| query | processed_MB | Charges_yen | cache_hit |
+----------------------------------+-------------------+----------------------+-----------+
| select | 9.678291320800781 | 0.009451456367969513 | false |
| 'pf part+cluster', | | | |
| partid, | | | |
| clusterdid, | | | |
| CURRENT_TIMESTAMP() t | | | |
| from `ml_dataset.bigdata_for_ev` | | | |
| where num_col1=12091139 | | | |
| and partid = 10 | | | |
| and clusterdid=9700146 | | | |
+----------------------------------+-------------------+----------------------+-----------+考察
Bigqueryのコンセプトどおり、パーティション、クラスタリングが機能している。
フルスキャンだとprocessed_MBが約2000MBだが、パーティション指定では22MB
クラスターキー指定では9.6MB程度までスキャンが減っている。
##Bigqueryの性能検証 Advanced
目的
下記の検証からBigqueryの内部的な動きを理解する。
1.パーティションキー&クラスターキーを指定した場合のスキャン開始位置
パーティションキーに加えクラスタキーを指定した場合は、対象パーティションの頭から対象クラスターキーまでスキャンするか?
(後のクラスターキーほどスキャン量が多くなる)
それとも、途中をスキップしてスキャン範囲を小くする仕組みがあるか?
もし、そのような仕組みがあるならパーティションのサイズを大きめにすることも可能ではないか?
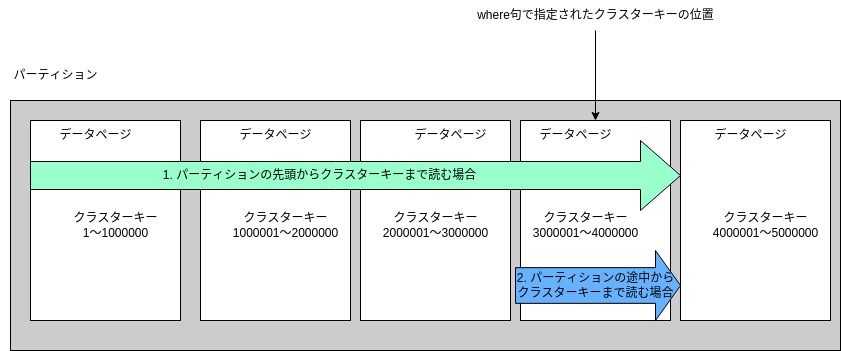
上記図の1.の緑矢印の場合は、必ずパーティションの先頭からスキャンを開始するため、指定されたクラスターキー次第でスキャン量が変化する。
上記図の2.の青矢印のようにスキャンする場合は、常に一定の量をスキャンする。
2.パーティション指定なし、クラスターキー指定なしで高速化
パーティション指定なし、クラスターキー指定なしだと必ずフルスキャンするか?
それともシーケンシャルに増加するような項目なら最小限のデータページのみスキャンするか?
※ DBによっては対象ページ内の最小値、最大値を統計情報として保有している。この情報からスキャンするデータページ
を絞り込める。Bigqueryにも同様の仕組みが備わっているのか?
検証結果
1.パーティションキー&クラスターキーを指定した場合のスキャン開始位置
select
'pf part+cluster min',
partid,
clusterdid,
num_col1,
CURRENT_TIMESTAMP() t
from
`ml_dataset.bigdata_for_ev`
where partid = 10
and clusterdid=9500000; -- at [2:1]
+---------------------+--------+------------+----------+---------------------+
| f0_ | partid | clusterdid | num_col1 | t |
+---------------------+--------+------------+----------+---------------------+
| pf part+cluster min | 10 | 9500000 | 18500113 | 2023-12-17 01:38:17 |
+---------------------+--------+------------+----------+---------------------+
+-----------------------------+-------------------+----------------------+-----------+
| query | processed_MB | Charges_yen | cache_hit |
+-----------------------------+-------------------+----------------------+-----------+
| select | 9.678291320800781 | 0.009451456367969513 | false |
| 'pf part+cluster min', | | | |
| partid, | | | |
| clusterdid, | | | |
| num_col1, | | | |
| CURRENT_TIMESTAMP() t | | | |
| from | | | |
| `ml_dataset.bigdata_for_ev` | | | |
| where partid = 10 | | | |
| and clusterdid=9500000 | | | |
+-----------------------------+-------------------+----------------------+-----------+select
'pf part+cluster middle',
partid,
clusterdid,
num_col1,
CURRENT_TIMESTAMP() t
from
`ml_dataset.bigdata_for_ev`
where partid = 10
and clusterdid=10000000; -- at [2:1]
+------------------------+--------+------------+----------+---------------------+
| f0_ | partid | clusterdid | num_col1 | t |
+------------------------+--------+------------+----------+---------------------+
| pf part+cluster middle | 10 | 10000000 | 32993260 | 2023-12-17 01:44:01 |
+------------------------+--------+------------+----------+---------------------+
+--------------------------------+--------------------+----------------------+-----------+
| query | processed_MB | Charges_yen | cache_hit |
+--------------------------------+--------------------+----------------------+-----------+
| select | 10.361503601074219 | 0.010118655860424042 | false |
| 'pf part+cluster middle', | | | |
| partid, | | | |
| clusterdid, | | | |
| num_col1, | | | |
| CURRENT_TIMESTAMP() t | | | |
| from | | | |
| `ml_dataset.bigdata_for_ev` | | | |
| where partid = 10 | | | |
| and clusterdid=10000000 | | | |
+--------------------------------+--------------------+----------------------+-----------+select
'pf part+cluster max',
partid,
clusterdid,
num_col1,
CURRENT_TIMESTAMP() t
from
`ml_dataset.bigdata_for_ev`
where partid = 10
and clusterdid=10499999; -- at [2:1]
+---------------------+--------+------------+----------+---------------------+
| f0_ | partid | clusterdid | num_col1 | t |
+---------------------+--------+------------+----------+---------------------+
| pf part+cluster max | 10 | 10499999 | 14000142 | 2023-12-17 01:45:00 |
+---------------------+--------+------------+----------+---------------------+
+-----------------------------+----------------+-----------------------+-----------+
| query | processed_MB | Charges_yen | cache_hit |
+-----------------------------+----------------+-----------------------+-----------+
| select | 2.848388671875 | 0.0027816295623779297 | false |
| 'pf part+cluster max', | | | |
| partid, | | | |
| clusterdid, | | | |
| num_col1, | | | |
| CURRENT_TIMESTAMP() t | | | |
| from | | | |
| `ml_dataset.bigdata_for_ev` | | | |
| where partid = 10 | | | |
| and clusterdid=10499999 | | | |
+-----------------------------+----------------+-----------------------+-----------+考察
クラスターキー指定ではパーティションの頭から対象クラスターキーまでスキャンするわけではなく、
対象のデータページに絞り込んでスキャンできるようである。
いつもクラスターキーを指定するようなテーブルの場合は、少な目のパーティション数にしても問題ないようである。
2.パーティション指定なし、クラスターキー指定なしで高速化
select
'pf seqid only',
partid,
clusterdid,
seqid,
CURRENT_TIMESTAMP() t
from
`ml_dataset.bigdata_for_ev`
where seqid = 9500000; -- at [2:1]
+---------------+--------+------------+---------+---------------------+
| f0_ | partid | clusterdid | seqid | t |
+---------------+--------+------------+---------+---------------------+
| pf seqid only | 10 | 9500000 | 9500000 | 2023-12-17 02:24:18 |
+---------------+--------+------------+---------+---------------------+
+-----------------------------+-------------------+----------------------+-----------+
| query | processed_MB | Charges_yen | cache_hit |
+-----------------------------+-------------------+----------------------+-----------+
| select | 9.678291320800781 | 0.009451456367969513 | false |
| 'pf seqid only', | | | |
| partid, | | | |
| clusterdid, | | | |
| seqid, | | | |
| CURRENT_TIMESTAMP() t | | | |
| from | | | |
| `ml_dataset.bigdata_for_ev` | | | |
| where seqid = 9500000 | | | |
+-----------------------------+-------------------+----------------------+-----------+select
'pf randum colum only',
partid,
clusterdid,
num_col1,
CURRENT_TIMESTAMP() t
from
`ml_dataset.bigdata_for_ev`
where num_col1 = 18500113; -- at [2:1]
+----------------------+--------+------------+----------+---------------------+
| f0_ | partid | clusterdid | num_col1 | t |
+----------------------+--------+------------+----------+---------------------+
| pf randum colum only | 10 | 9500000 | 18500113 | 2023-12-17 02:24:59 |
+----------------------+--------+------------+----------+---------------------+
+------------------------------+--------------------+-------------------+-----------+
| query | processed_MB | Charges_yen | cache_hit |
+------------------------------+--------------------+-------------------+-----------+
| select | 2288.8927001953125 | 2.235246777534485 | false |
| 'pf randum colum only', | | | |
| partid, | | | |
| clusterdid, | | | |
| num_col1, | | | |
| CURRENT_TIMESTAMP() t | | | |
| from | | | |
| `ml_dataset.bigdata_for_ev` | | | |
| where num_col1 = 18500113 | | | |
+------------------------------+--------------------+-------------------+-----------+考察
パーティションキー、クラスターキーがなくても高速化される仕組みが備わっているように思われる。
恐らくデータページ内の最大値、最小値を統計情報として保有して可能なら最小限のスキャン
となるようにプランニングするのだろう。
パーティションキー、クラスターキー指定なしでも高速な場合があることを
理解しておけば、誤った性能検証をしてしまうことを避けられる。
しかし、余程のことがなければこの特性を用いてチューニングするのはやめた方がいい。
データ特性に依存するので、データ特性が変わると影響を大きく受ける。