ETLのメモリはDBのように、アクセス頻度の高いデータをメモリに載せてディスクアクセスの頻度を削減するような使い方はしない。
ソート、ソートJOIN、Group by、ランキング処理等のレコード間の関連を見なければならない処理では、メモリにデータを溜める必要がある。もし、メモリが足りなければディスクの一時領域に保管される。
重要な処理について目標処理時間を達成するために、上記の処理についてメモリをサイジングすれば良い。例えばソートなら全データ量のデータサイズをベースに1.5倍等、余裕を見て確保する程度で良いだろう。(加えて、製品で要求される最小メモリサイズは必要である)
メモリが不足した場合はどうなるか?
処理時間の要件を満たすなら、無理にメモリを準備する必要はない。ストレージIOが多くなり処理時間を長くなるが、最近はSSDやクラウド上の高性能のストレージを使えば十分に高速である。しかし、サイジングするには、どの程度処理時間が長くなるかシュミレーションできる必要がある。その方法を記載する。
ソート例に考える。
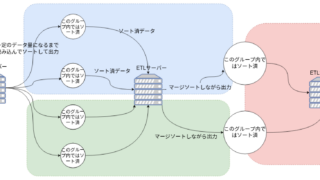
下記の図はマージソートでデータを分割して処理しているところを表している。○はデータである。最初にETLサーバーはデータをソースから読み込んで一定のメモリ量になったら、メモリ上でソートしてディスクに出力する。下記の図では4回ソート、ディスク処理を繰り返ししている。次にソート済データを2つ同時に読み込み、読み込みながらマージソートしてディスクに書き出す。ここがポイントで既にソート済なので、マージするときは2つのファイルから読み込んだデータを1行ずつ比較しながら小さい方を出力すればよい。この方法だとメモリにデータを溜める必要がない。
次のポイントは最初に分割する数である(下記では4つ)。この分割するファイル数が多くなればなるほど、ストレージへのIO回数が増える。ここでは2回の出力と2回の読み込みを行っているが、8分割だと3回の出力と3回の読み込みが必要となる。
つまり下記ではメモリ内で処理が完結する場合と比較して データ量÷出力性能(100MB/s等)×2+データ量÷入力性能(100MB/s等)×2 のIO時間が追加で必要となる。
尚、ほとんどの場合はIOボトルネックとなるためCPU時間は無視している。私が実業務でシュミレーションする場合も、このようなケースでは通常はCPU時間は考慮しない。(しかし、並列処理を行う等でCPUが足りていないような状況では考慮する)

上記はソートの例だがGroup Byやランキング処理は、レコードを集計してデータ量が減るためソートよりもIO負荷の影響は小さい。
補足
並列に処理を実行する場合は同時に使うメモリ量でサイジングする。
メモリを増やしOSのバッファキャッシュを大きくすることでIO性能を高速化することができるが、サイジングというよりはチューニングなので別の記事で詳細を記載する。