ETLのCPUをサイジングするときの基本的な考え方を記載する。いろいろなサイジング方法があるが私が使っているものである。常に実測してみて見積るのでは作業コストが膨らんでしまう。また、実測はテストデータの特性やキャッシュの状態に依存し精度の高い測定はかなり難しい。
重要度の低い処理はシュミレーションのみでサインジングして、重要な処理では実測とシュミュレーションで大きな差がないことを確認するアプローチが良いだろう。
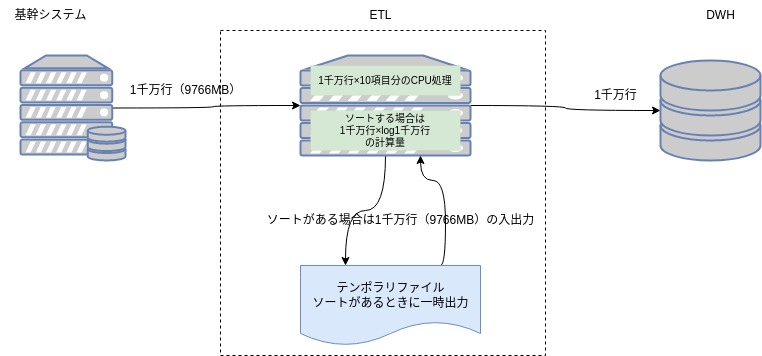
以下の処理を前提に考える。

下記の表”前提”の条件だとすると表”CPUの処理時間”のとおり、CPUの処理は10秒規模である。一方データベースIOは下記表のIO性能とデータサイズからすると40秒程度である。IOボトルネックなのでCPUは下記の想定のもので問題ないということになる。
仮にソートが発生した場合は下記”ソートを実行する場合”のとおり、23秒程度である。一方、ソート時に中間ファイルに入出力する時間は38秒×2で80秒程度となり、やはりIOボトルネックである。
しかし、下記の表”CPUの処理時間”の(参考)1バイトずつ処理をする場合のとおり、計算量が多いETL処理がある場合は、CPU処理が支配的になり、”CPUのグレードアップ”、”コア追加+マルチスレッド化”等の対応が必要となる。
もし、もっと簡略化してシュミュレーションする場合は、下記”(参考)CPUで処理できるデータサイズ”の値を実測しておいて、IO性能と比較することもできる。(前述のとおり、データ傾向やキャッシュの問題でぶれるリスクがある)

上記のとおり、非常に単純な例でもサイジングは複雑である。実際は、もっと多くのパラメータがあるので誰でも使えるサイジングシートのようなもので対応するのは非現実的なのがわかると思う。まさにサイジングはデータエンジニアの腕の見せ所とも言える。